Enforcing Distributed Rate Limiting with Hazelcast and Bucket4j
Hands-on guide on enforcing distributed rate limiting for multiple instances with Bucket4J and Hazelcast.
Rate limiting is a crucial aspect of any scalable system, especially web services. It helps to control the traffic and limit the number of requests from a client within a specific time frame.
When an application moves from a single instance to a distributed system, implementing rate limiting can become increasingly complex, on both sides, on the client as well on as the server.
In a distributed environment, rate limiting mechanisms must be consistent across multiple nodes to enforce the rate limits effectively. This is where distributed rate limiting comes into play.
To tackle this challenge, we'll implement distributed rate limiting utilizing Bucket4j as our main library for rate limiting, alongside its hazelcast extension module to distribute the "bucket state" across multiple instances of our service. So let's get going!
The Scenario
Rate limiting can be applied at various stages, also depending on if we are the service provider or the consumer of a service.
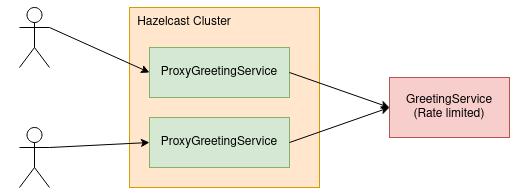
In this posts' scenario, we assume to be the consumer (ProxyGreetingService), who's requesting a service API which enforces rate limiting (GreetingService).
Our consumer application will be built to run as multiple instances, so when requesting the rate limited API, we have to distribute our request bucket state such that all instances of our service know if and how many requests we can still execute.
The rate limited Service
The rate limited GreetingService will just yield a very original greeting message. 😅
const express = require('express');
const rateLimit = require('express-rate-limit');
const app = express();
// Apply rate limit to all requests: 5 requests per minute
app.use('/greet', rateLimit({
windowMs: 60 * 1000, // 1 minute
max: 5
}));
app.get('/greet', (req, res) => {
res.json({ message: 'Hello, World, I\'m rate limited! :)' });
});
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});
Rate-limited GreetingService written in JavaScript with express
It will enforce a max request cap of 5 requests per minute calculated on the basis of a running window.
Upon calling the request 6 times within a minute, we receive the expected output.
curl http://localhost:3000/greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:3000/greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:3000/greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:3000/greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:3000/greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:3000/greet
> Too many requests, please try again later.Distributing rate limits with Bucket4j and Hazelcast
Now that we have our rate limited GreetingService up and running, it's time for the real deal. We'll implement our GreetingProxyService, which requests the rate limited GreetingService.
<dependencies>
<!-- Bucket4j for rate limiting -->
<dependency>
<groupId>com.bucket4j</groupId>
<artifactId>bucket4j-core</artifactId>
<version>8.3.0</version>
</dependency>
<!-- Bucket4j hazelcast integration -->
<dependency>
<groupId>com.bucket4j</groupId>
<artifactId>bucket4j-hazelcast</artifactId>
<version>8.3.0</version>
</dependency>
<!-- Hazelcast -->
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
</dependency>
<!-- ... -->
</dependencies>Partial pom.xml
Before writing any code, we make sure to add the necessary dependencies for bucket4j-core as our core library to handle rate limiting, bucket4j-hazelcast in order to sync up our buckets via hazelcast, and hazelcast itself, the library which provides the IMDG cluster.
Having the necessary dependencies added, we can go on configuring our distributed rate limiting setup with Hazelcast and Bucket4j.
In our scenario, we'll use Hazelcasts embedded clustering capabilities to simplify the setup.
@Configuration
class RateLimitingConfiguration {
@Bean
fun hazelcastInstance() = Hazelcast.newHazelcastInstance()
@Bean
fun rateLimitingMap(hazelcastInstance: HazelcastInstance): IMap<String, ByteArray> =
hazelcastInstance.getMap("rate-limiters")
@Bean
fun hazelcastProxyManager(rateLimitingMap: IMap<String, ByteArray>) =
HazelcastProxyManager(rateLimitingMap)
@Bean
@Qualifier("greeting-service-limiter")
fun rateLimitingBucket(proxyManager: HazelcastProxyManager<String>): Bucket {
val configuration = BucketConfiguration.builder()
.addLimit(Bandwidth.simple(4, Duration.ofMinutes(1)))
.build()
return proxyManager.builder()
.build("greeting-service-limit", configuration)
}
}RateLimitingConfiguration.kt
We define a new basic HazelcastInstance bean, for which we fetch a new map for all our rate-limiters. In our case we'll fill it only with one entry as we are dealing only with one external service, but we could extend it for multiple of course.
As we can see, the real magic happens behind a HazelcastProxyManager of Bucket4j which wraps the Hazelcast IMap and provides a nice interface to build the rate limiting bucket configuration with.
We intentionally set the bucket limit to 4 requests per minute instead of 5 per minute, in order to not run into edge cases where our bucket would free a token some milliseconds before the corresponding server would, only due to latency issues or the likes.
Moving forward, we implement the GreetingClient which calls the GreetingService. However, it requests the Bucket4j bucket upon bean construction, and only executes a request if there is a token available in the bucket.
@Service
class GreetingClient(
private val restTemplate: RestTemplate,
@Qualifier("greeting-service-limiter") private val bucket: Bucket
) {
fun greet(): GreetingDTO {
bucket.asBlocking().consume(1)
return restTemplate.getForObject("http://localhost:3000/greet",
GreetingDTO::class.java)!!
}
}
data class GreetingDTO(
val message: String
)
GreetingClient.kt
If there is currently no token available, it will queue up and wait until one becomes available. This method blocks the current thread, which is what we intend to do in this example.
bucket.tryConsume() which wouldn't block the thread but will return false when no token is left in the bucket. It's then up to the developer how to proceed in such a case.Having the Client ready, the only thing left is to create an API endpoint for our GreetingProxyService itself, which in this example just forwards the call to our GreetingService.
@RestController
class GreetingProxyApi(private val greetingClient: GreetingClient) {
@GetMapping("proxy-greet")
fun rateLimitingCall() = greetingClient.greet()
}GreetingProxyApi.kt
It makes itself available under the "proxy-greet" path such that we can distinguish the proxy calls more easily from the direct calls.
Verifying the Limits
As a last step, we should of course also verify our setup. So we build our GreetingProxyService and boot up multiple instances via java -jar target/bucket4j-hazelcast.jar & .
...
2023-08-27T20:57:59.699+02:00 INFO 11789 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 39647 (http) with context path ''
2023-08-27T20:58:12.098+02:00 INFO 11946 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 45947 (http) with context path ''
2023-08-27T20:58:11.840+02:00 INFO 11946 --- [ration.thread-0] c.h.internal.cluster.ClusterService : [192.168.1.112]:5702 [dev] [5.2.4]
Members {size:2, ver:2} [
Member [192.168.1.112]:5701 - fda5e0d5-a0f5-465b-8052-5fa1b0b92d37
Member [192.168.1.112]:5702 - 1afee9c9-578d-476a-b76f-073542057992 this
]
...We can see that both applications started up on different ports, and connected to the Hazelcast cluster successfully.
Now when we execute some curls against our two new GreetingProxyServices, we can see that no more rate limit errors occur.
curl http://localhost:39647/proxy-greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:45947/proxy-greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:39647/proxy-greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:45947/proxy-greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:39647/proxy-greet
> {"message":"Hello, World, I'm rate limited! :)"}
curl http://localhost:45947/proxy-greet
> {"message":"Hello, World, I'm rate limited! :)"}We notice a slight delay when executing the last statements, as our client applies rate limiting and blocks the requesting thread until a token becomes available in the rate limiting bucket, which is shared between both instances. Great!
Congratulations
Very nice. You've just implemented a distributed rate limiting client library for a rate limited service API with Bucket4j and Hazelcast.
If you'd like to fetch all the code in one go, you can grab the full code of both services from this repository.