
Enhancing HumSet: Improving Humanitarian Crisis Response with AdapterFusion
Humanitarian Crisis Response is a very delicate field, as humanitarian crisis responses have to be very fast, but at the same time also very well-informed, to provide meaningful help within an area.
Naturally, experts within the field have to constantly read and process a lot of reports and articles about a crisis area, in order to be able to provide meaningful help. A very time-consuming but crucial step.
However, as this seems to be a process which can be efficiently tackled with Natural Language Processing systems, HumSet has been introduced, a dataset about humanitarian crisis ranging from 2018 to 2021, annotated by experts.
HumSet itself does not only provide the research community with an annotated dataset, but also with a hierarchical classification framework of 5 separate categories (sectors, pillars and subpillars) developed by experts, to label the needs within an area fast and reliably.
In the following, we investigate if, by combining the knowledge of those 5 categories, we can achieve even better results than the baseline model results provided by HumSet.
Building Blocks
Before diving into the technical details of our task at hand, let's quickly discuss the main building blocks we'd want to utilize and build upon to achieve our goal.
What is HumSet?
HumSet (Dataset of Multilingual Information Extraction and Classification for Humanitarian Crisis Response) by Fekih et al. is a multilingual dataset of humanitarian crisis response annotated by experts of the domain. It is composed out of a wide variety of English, French and Spanish documents.
In addition to the annotated data, it introduces a hierarchical classification framework to ease the collection of new data as well as standardize the classification practices of data within the domain.
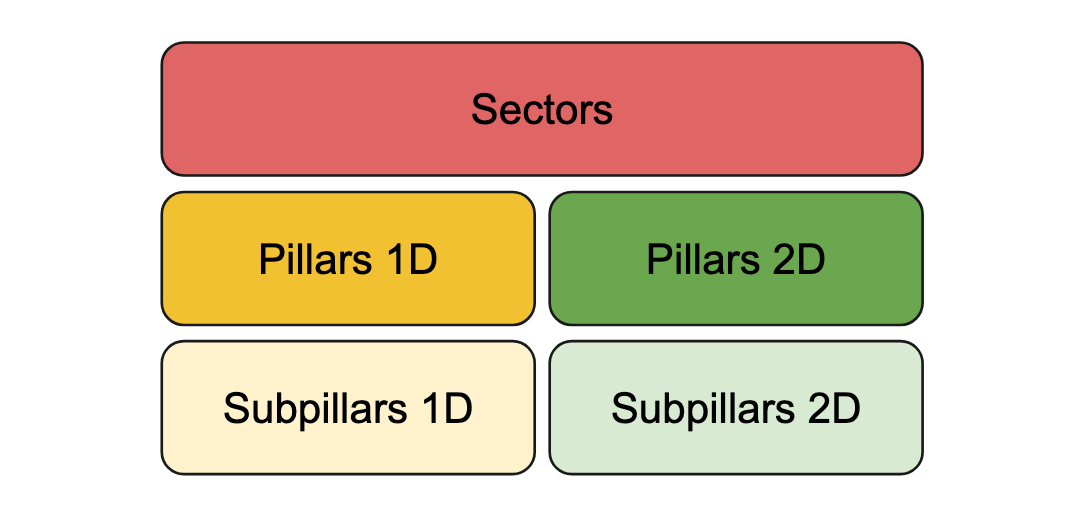
For each document in the corpus, it provides selected snippets as well as their accompanying classification labels according to the classification framework. It covers various crisis scenarios from 2018 up to 2021 in 46 humanitarian response projects. The dataset itself contains about 17k annotated documents.
An example of such a snippet:
“[October 29, Raqqa, # of cases increases] Until today, the number of cases registered with the Coronavirus in the Autonomous Administration regions in general reached 4164 cases, of which 470 were declared cases in the city of Raqqa, while observers in the Health Committee of the Autonomous Administration in northeastern Syria expect that the real numbers will be significantly higher than those declared given the reluctance of many civilians to conduct tests and take swabs.”
Sectors:
Health
Pillars 1D:
Covid-19
Pillars 2D:
Impact
Subpillars 1D:
Covid-19
->
Cases
Subpillars 2D:
Impact
->
Impact On People
Aside from the introduction of the dataset, it provides us with performance metrics of strong baseline models for information extraction as well as information classification on the dataset.
Adapters and AdapterFusion
It's common in transfer learning to completely fine-tune the model on a specific downstream task. However, training a separate model for each task is not quite efficient. Not only substantial computational resources are consumed, but it also risks catastrophic forgetting in a multi-tasking scenario, a phenomenon where the model forgets how to perform old tasks while learning new ones.
This is where Adapters and Adapter layers come into play. Adapters, formally introduced in the paper Parameter-Efficient Transfer Learning for NLP by Houlsby et al., represent non-linear feed-forward down and up projection layers embedded within each transformer layer of the model.
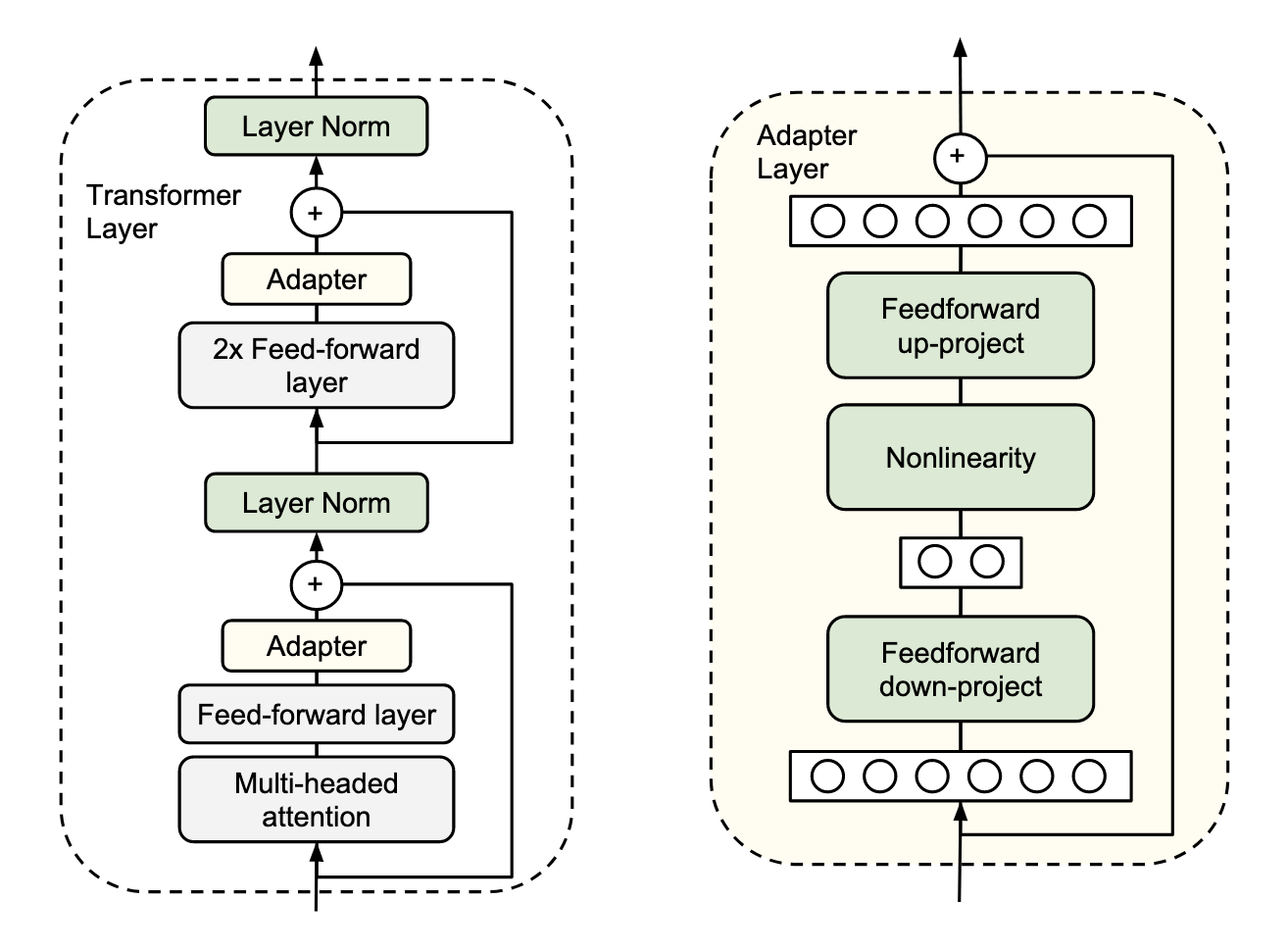
During the training process, the original models parameters are not altered – only the Adapter weights are trained. Afterward, these Adapter layers can then be extracted and used as a condensed representation, or distilled knowledge, of the specific task at hand.
However, the distilled knowledge encapsulated within the Adapters can't be effectively merged without again risking catastrophic forgetting. To address this issue, AdapterFusion has been introduced in the paper AdapterFusion: Non-Destructive Task Composition for Transfer Learning by Pfeiffer et al.
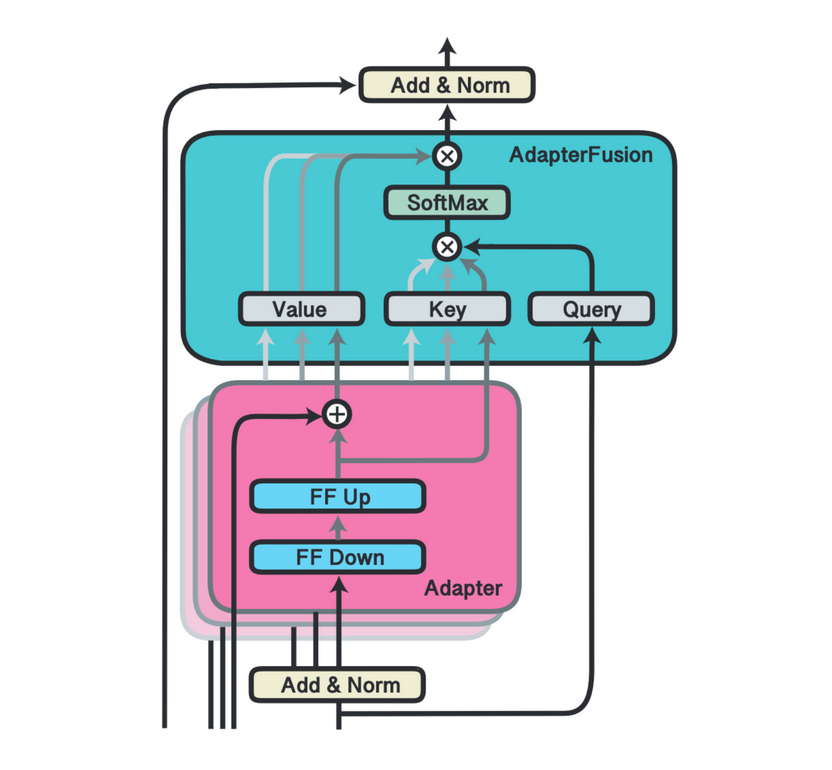
Like Adapter layers, AdapterFusion attention layers are situated within each transformer layer of the model. But in this case, both the original model's weights and the Adapter weights are fixed. Instead, only the AdapterFusion attention layers are trained to attend to the right mix of outputs of several Adapters.
This approach allows for efficient information combination of the Adapters using AdapterFusion layers.
HumSet Baseline Results
Before experimenting with different architectures utilizing Adapters and AdapterFusion, we'll quicky discuss the results of the paper, which we'd like to improve upon.
In the HumSet paper, several models of different sizes and architectures were applied to the five categories of the humanitarian classification framework. Performance has been measured via F1 score and precision metrics for each category, with macro-average caluclations reported to account for the unbalanced nature of the dataset.
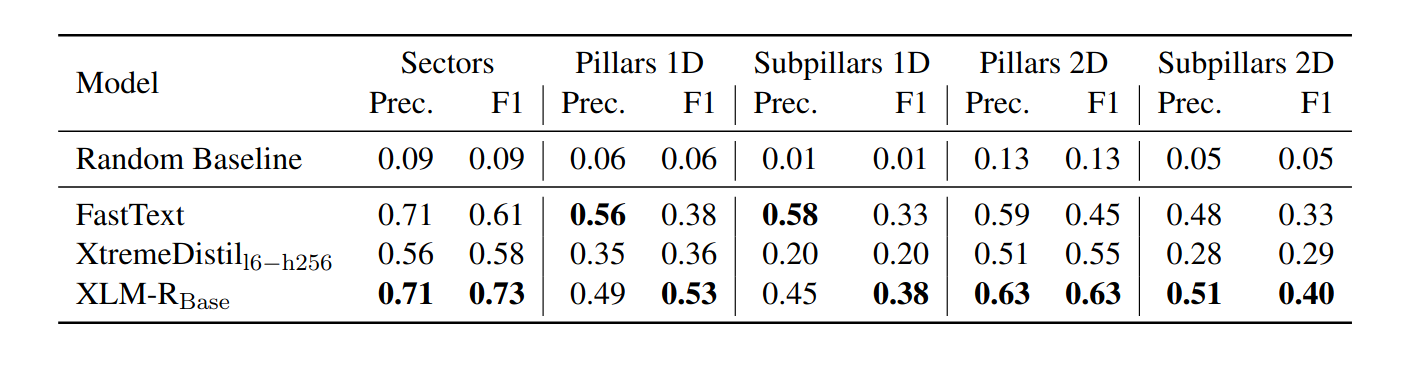
Our primary focus lies on the results of the two transformer based models, XLM-RoBERTa Base and Xtreme-Distil l6-h256. Both models performed well overall, although each exhibited lower performance in the categories subpillars 1d and 2d. As a result, the subsequent evaluation or our AdapterFusion based approaches will also be conducted on these two models.
To ensure comparable results with the original HumSet paper, the baseline code provided with the HumSet dataset will be used and extended.
Proposed Approaches
As we have reviewed the results of the original paper, let's dig into what needs to be done in order to start experimenting with AdapterFusion, and think about some of the possible approaches we can implement in order to improve upon the presented results.
Individual Adapter Training
In order to utilize AdapterFusion, individual Adapters must first be trained. We'll modify the baseline code in order to consecutively train individual Adapters for each sector, pillar, and subpillar within the classification framework. During this training, the weights of the baseline model will be kept constant, allowing only for the Adapter layers to be updated.
This way, the specific knowledge of the downstream classification task is distilled into the Adapter weights, while the base model continues to provide context for the sequence inputs.
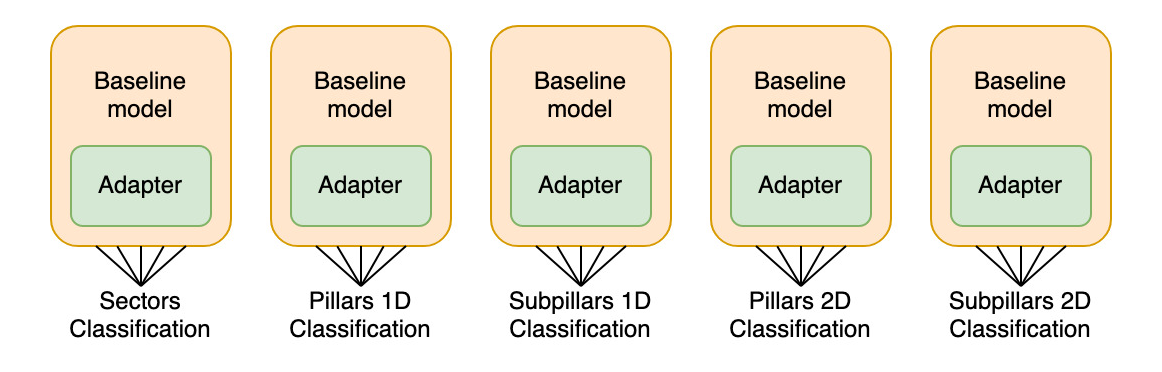
This procedure will result in the extraction of Adapter layer weights along with the weights of the classification head used for making predictions.
Consequently, five Adapter configurations will be obtained, each corresponding to a different category in the framework. These will be used for future applications of AdapterFusion.
Single-Head AdapterFusion Approach
The first approach we'll experiment with is the training of a single-head AdapterFusion model. After the individual Adapters have been trained, they are loaded into the model simultaneously, each producing predictions for its specific category.
Additional AdapterFusion layers are then added to fuse the outputs of the five independently trained Adapters, yielding refined predictions for a single category classification task.
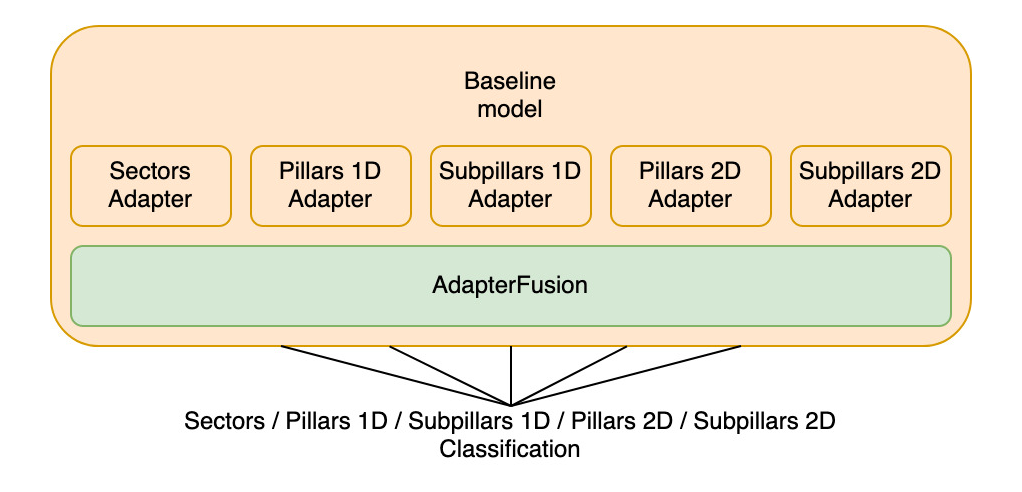
This architecture allows the AdapterFusion layers to balance the outputs of the five pre-trained Adapters to optimize results. This process is repeated for all five category classification tasks, with a new AdapterFusion configuration created each time which fuses the insights of the pre-trained Adapters for a focused classification of the downstream classification task.
Given the significant similarities between this approach and the original baseline setup, where five models are trained independently, this method offers a rigorous framework for assessing whether and how much performance can be improved compared to a fully fine-tuned model that lacks the ability to integrate knowledge from multiple sources.
Multi-Head AdapterFusion Approach
The second approach we'll experiment with, similarly to the single-head approach, again utilizes the pre-trained Adapters, and tries to combine them via AdapterFusion.
However, this time we try to combine the knowledge and utilize the gained insights to predict labels for all categories simultaneously, effectively reducing the need for 5 separate models to 1 model only.
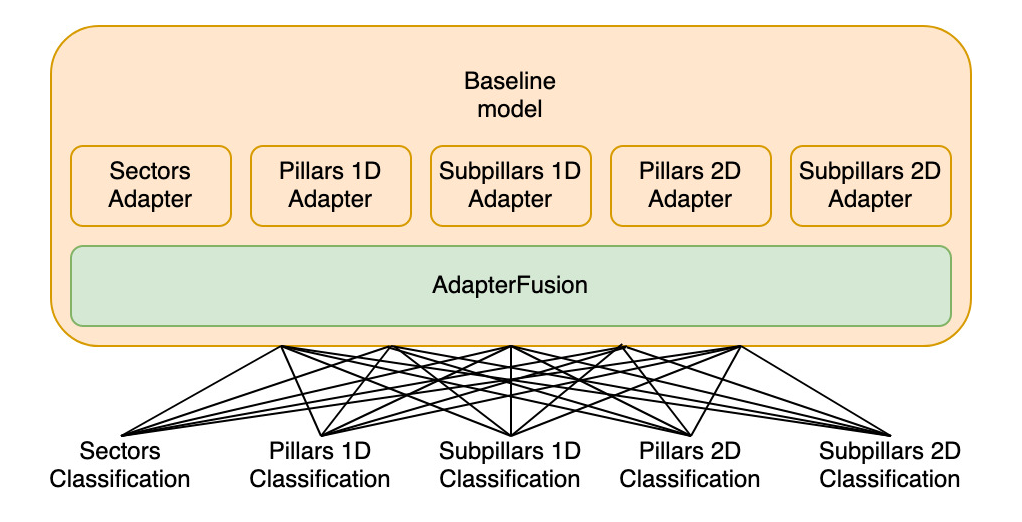
To achieve this, we add multiple classification heads to the model, one for each category. Given that we are now effectively operating in the field of multi-task classification, we anticipate that it may be more challenging for the model to strike a balance between the needs of all 5 classification heads.
However, in a production scenario, the advantages of maintaining a single model, capable of potentially predicting the labels for all categories with only one inference pass, may outweigh a performance decline, depending on the severity of such a decrease, hence we’ll include this approach into our experiment setup.
Results
After we've established and refined our ideas about the proposed architectures, we'll start off training and see the results.
Before we do this however, we make sure that by using the provided baseline code parts of the original paper, we can indeed verify and reproduce the results of the original paper.
Reproduction Results
Unfortunately, the results obtained using the code provided in the HumSet paper did not exactly match those reported in the original study. The results, while representative, do not seem to reflect the maximum achievable performance.
This discrepancy likely arises from the generic nature of the provided code, which seems to be intended as a skeleton for working with HumSet, rather than a blueprint for exactly replicating the top-performing results.
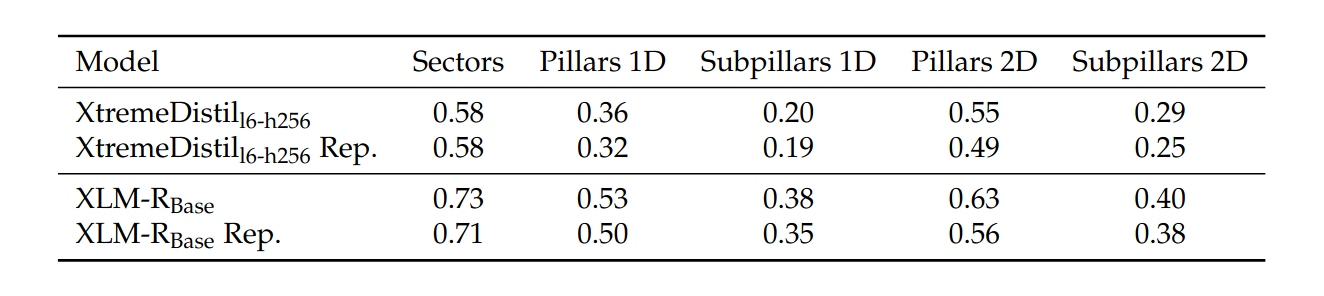
The code lacks some methods and detailed strategies outlined in the research paper, such as assuming the same fixed hyperparameters for every category and not including an algorithm for extensive threshold tuning. Variations in the versions of libraries and tools used could also have contributed to the divergent results.
Despite these differences, the reproduced results will serve as our baseline for comparison. The goal is to modify and enhance the codebase using the proposed AdapterFusion approaches.
The assumption is that if these modifications improve performance with this more generic codebase, similar gains can be expected when these changes are incorporated into the specific setup that generated the original paper's exact results.
This approach aims to ensure that enhancements can be validated in a consistent and comparable manner.
Single-Head AdapterFusion Results
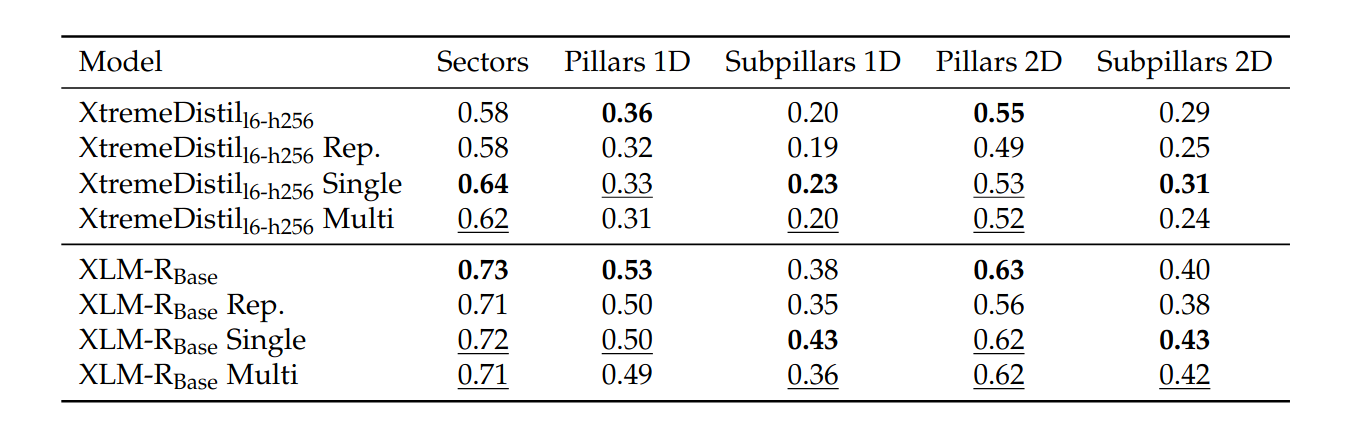
The approach of combining the knowledge of all five categories for each downstream task yields promising performance gains. Even in cases without gains, the performance stays on par with the reproduction results.
In the results tables below, bold entries showcase the overall best result, while underlined entries showcase where our approach was able to outperform or at least stay on par with the reproduction results.
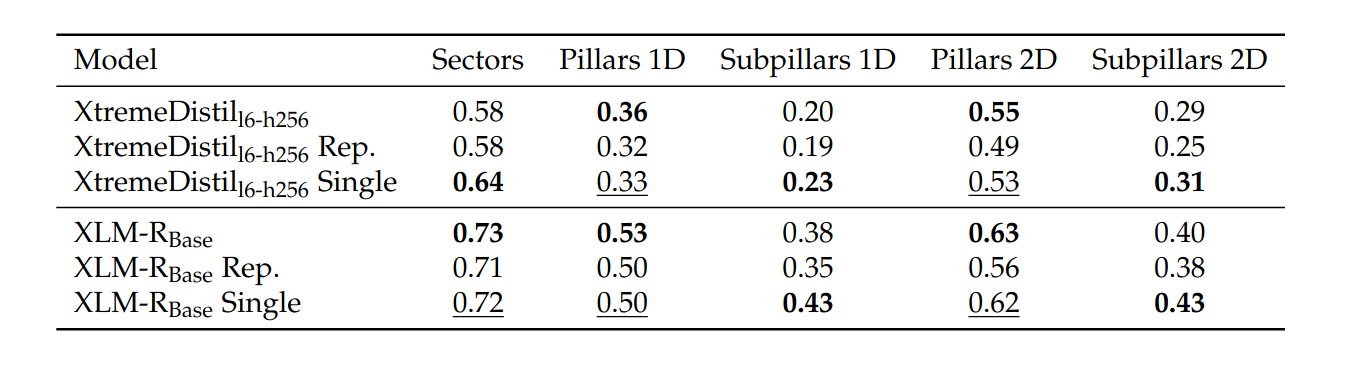
The single-head AdapterFusion approach outperformed the reproduction results across all categories for the XtremeDistil l6-h256 model and exceeded the official HumSet paper's results in three out of five categories. It also overcame the model's weakness in specific categories where the baseline model had its lowest scores.
For the larger XLM-RoBERTa Base model, the single-head AdapterFusion approach outperformed the reproduction results in four out of five cases and matched the fifth. In two cases, it outperformed the official HumSet results.
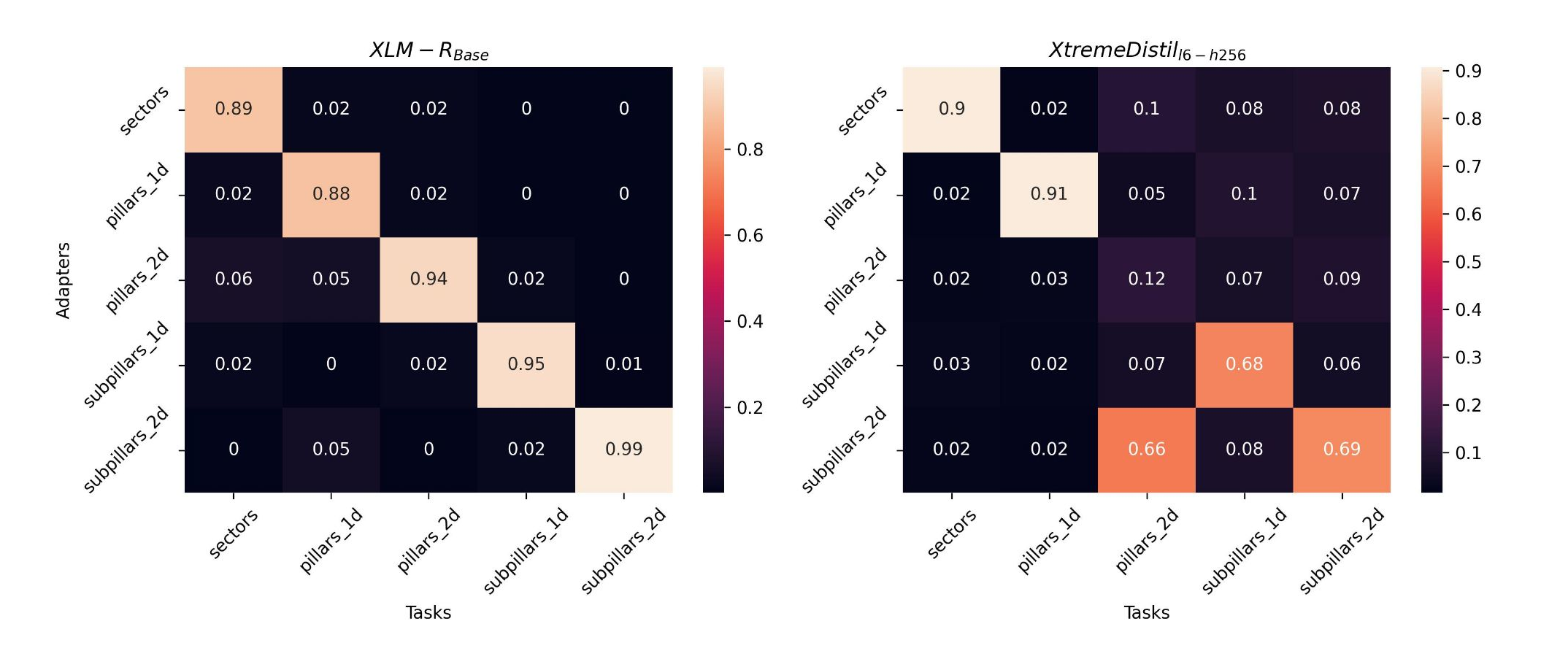
An examination of the trained weights of the attention mechanism of the AdapterFusion layers reveal that the model primarily focused on the outputs of the Adapters it was classifying for, incorporating 5-12% of the distilled knowledge provided by the other Adapters.
The smaller XtremeDistil l6-h256 model, with its lower capacity, used a more "clever" approach. It achieved effective knowledge combination by focusing on the output of the relevant Adapter and combined this with about 12% attention on its "origin" Adapter in certain categories.
This strategy enabled the XtremeDistil l6-h256 model to outperform all previous models in these categories. The smaller model seems to make larger gains than the larger XLM-RoBERTa Base in terms of performance improvements, indicating that knowledge combination is more effective for it.
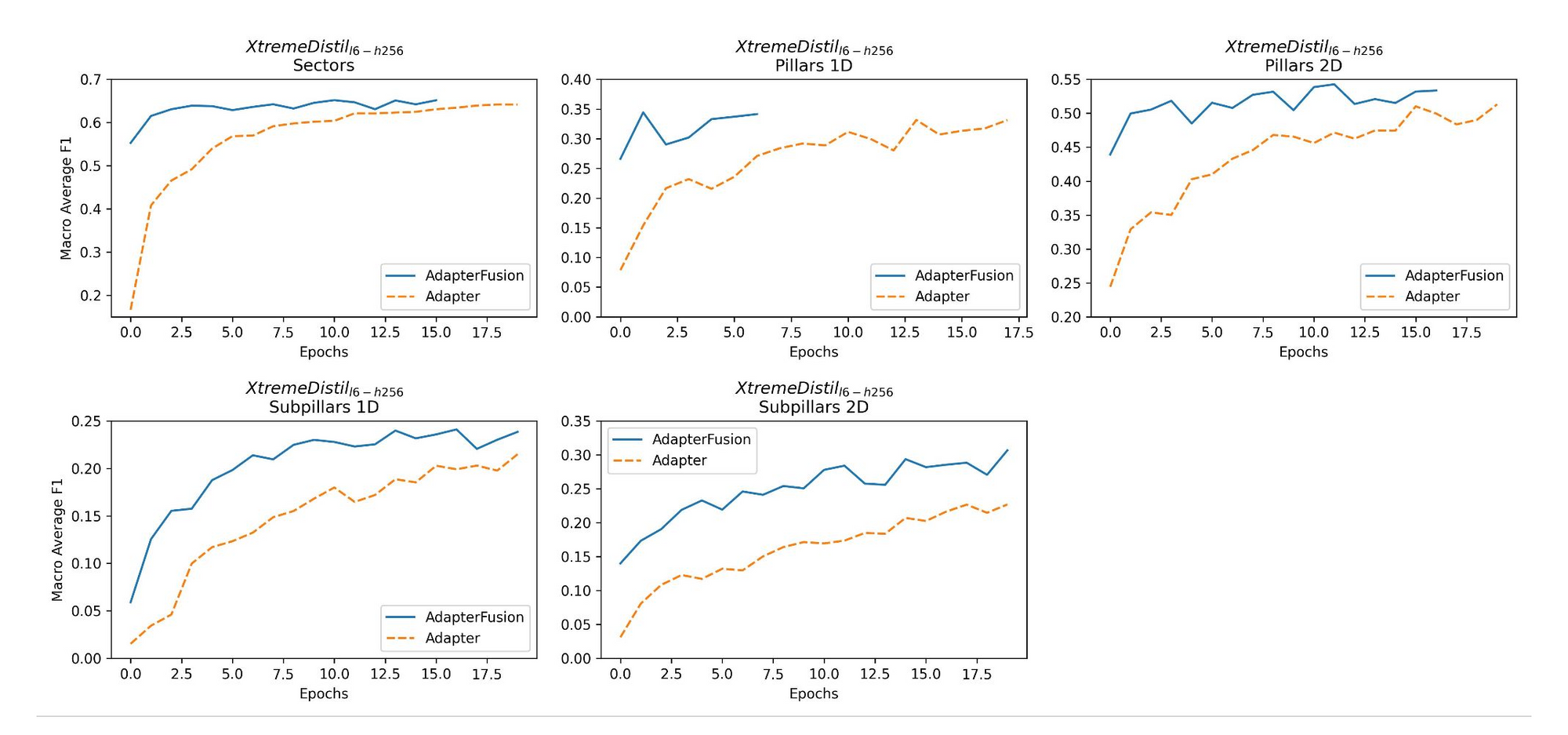
During training, the advantage of the AdapterFusion technique is evident in the consistently higher F1 scores measured on the validation set per epoch for both models, especially already early on in the training phase.
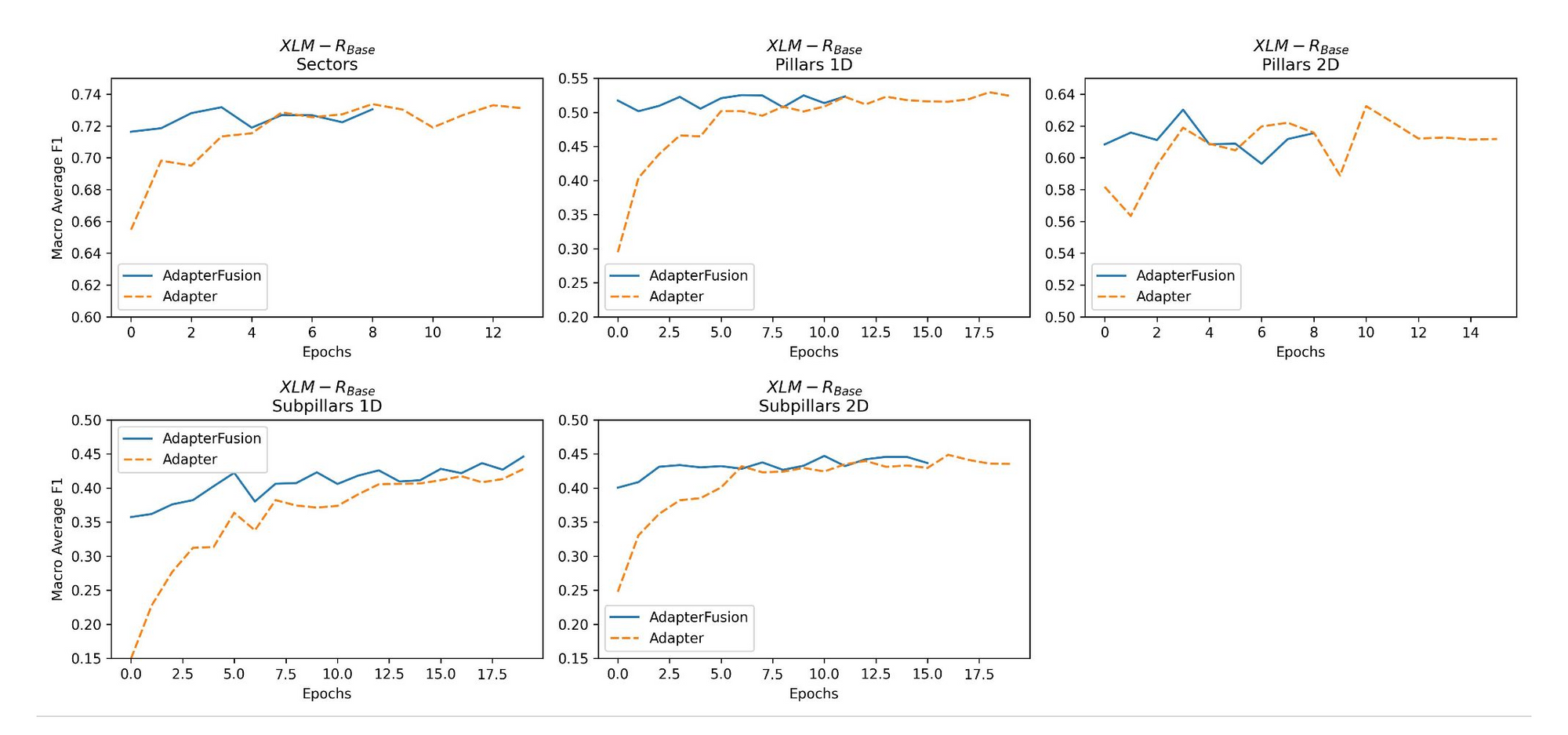
The F1 score starts quite high from epoch 0, indicating efficient use of the pre-trained Adapter, and improvements happen mostly in terms of different combination strategies of the outputs of the five Adapters.
Multi-Head AdapterFusion Results
The multi-head AdapterFusion approach yielded good results but fell short compared to the single-head AdapterFusion approach, as anticipated. This is likely due to the multi-task learning nature of the model, which needs to balance the requirements of all five classification heads.
Compared to the reproduction results, the XtremeDistil l6-h256-based multi-head model outperformed in 3 of the 5 categories, while the XLM-RoBERTa Base based model surpassed or matched the reproduction results in 4 out of 5 categories. However, compared to the single-head AdapterFusion approach, there is a noticeable performance decrease across all categories.
When observing the attention weights of the AdapterFusion layers in the multi-head model, it's clear that the degradation in performance results from a lack of focus on one downstream task.
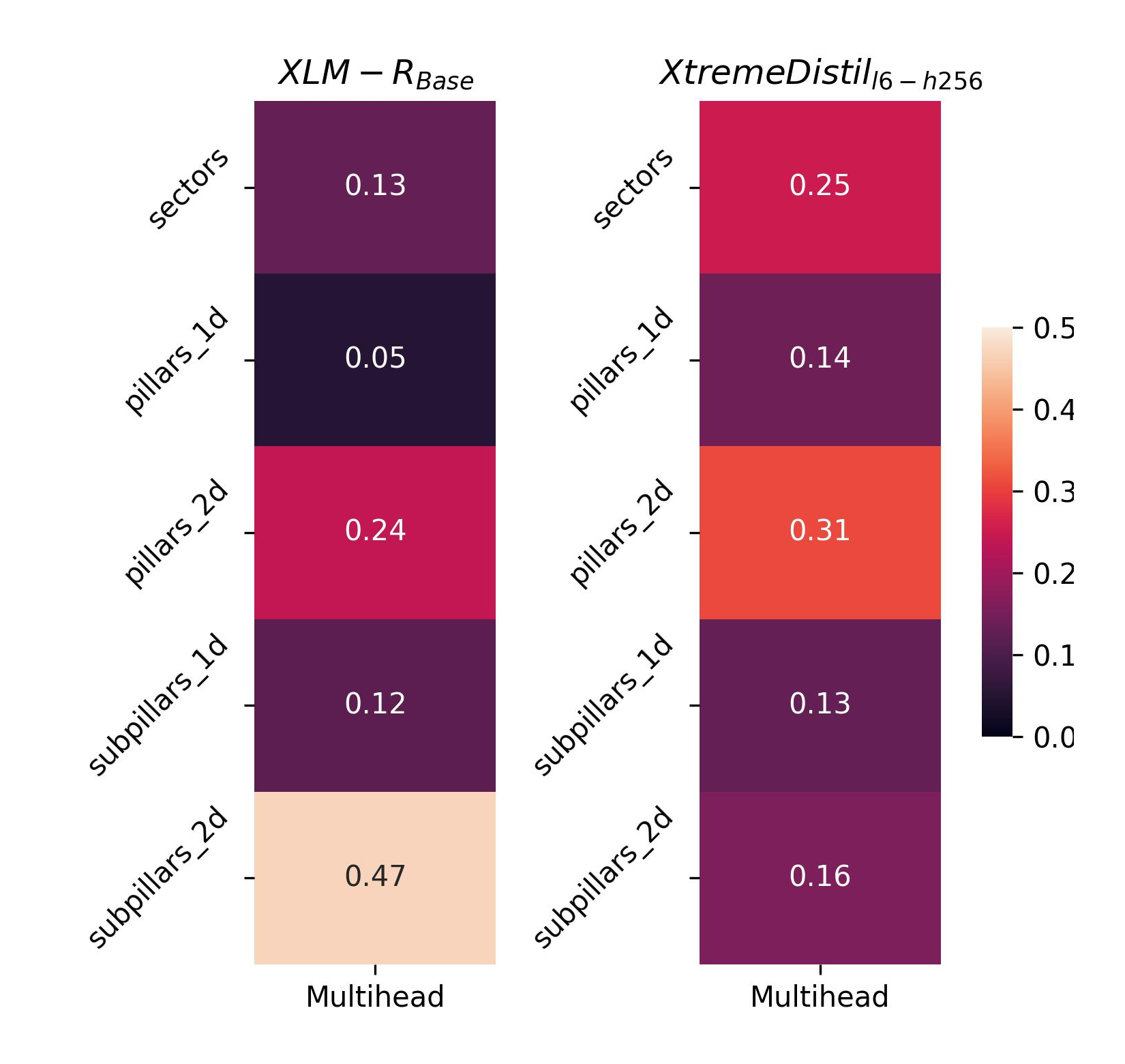
The attention scores vary broadly, which indicates a lack of effective knowledge sharing. Rather, the model seems to be attempting to strike a balance to reach overall acceptable results.
In essence, while the multi-head AdapterFusion approach is simpler and therefore attractive, it falls short due to the necessity of serving all five classification heads equally. This leads it to suffer from the same issues commonly associated with many other multi-task models.
Conclusion
In conclusion, we've discovered that single-head AdapterFusion outperforms multi-head AdapterFusion, achieving substantial improvements over our initial tests and the original HumSet paper, even without all technicalities implemented.
Importantly, the latest HumSet iteration introduces a new innovative architecture that further elevates the results.
Adapters and AdapterFusion have proven very useful in combining the knowledge of our different categories, offering a blend of accuracy, flexibility, and modularity that makes them ideal for fusing similar yet distinct downstream tasks which allow for improvements due to knowledge combination.


